最近一直在做leetcode上面关于字符串的题目,想着就来阅读一下String类的源码来深入理解String类的实现。String类是我们平时用的最多的一个类了,本篇文章阅读String类的源码,整理String类的设计与实现。本篇文章参考HollisChuang的博客成神系列
String定义
首先String类位于java.lang包下面,jdk源码对String类的一段描述(好长):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58/**
* The {@code String} class represents character strings. All
* string literals in Java programs, such as {@code "abc"}, are
* implemented as instances of this class.
* <p>
* Strings are constant; their values cannot be changed after they
* are created. String buffers support mutable strings.
* Because String objects are immutable they can be shared. For example:
* <blockquote><pre>
* String str = "abc";
* </pre></blockquote><p>
* is equivalent to:
* <blockquote><pre>
* char data[] = {'a', 'b', 'c'};
* String str = new String(data);
* </pre></blockquote><p>
* Here are some more examples of how strings can be used:
* <blockquote><pre>
* System.out.println("abc");
* String cde = "cde";
* System.out.println("abc" + cde);
* String c = "abc".substring(2,3);
* String d = cde.substring(1, 2);
* </pre></blockquote>
* <p>
* The class {@code String} includes methods for examining
* individual characters of the sequence, for comparing strings, for
* searching strings, for extracting substrings, and for creating a
* copy of a string with all characters translated to uppercase or to
* lowercase. Case mapping is based on the Unicode Standard version
* specified by the {@link java.lang.Character Character} class.
* <p>
* The Java language provides special support for the string
* concatenation operator ( + ), and for conversion of
* other objects to strings. String concatenation is implemented
* through the {@code StringBuilder}(or {@code StringBuffer})
* class and its {@code append} method.
* String conversions are implemented through the method
* {@code toString}, defined by {@code Object} and
* inherited by all classes in Java. For additional information on
* string concatenation and conversion, see Gosling, Joy, and Steele,
* <i>The Java Language Specification</i>.
*
* <p> Unless otherwise noted, passing a <tt>null</tt> argument to a constructor
* or method in this class will cause a {@link NullPointerException} to be
* thrown.
*
* <p>A {@code String} represents a string in the UTF-16 format
* in which <em>supplementary characters</em> are represented by <em>surrogate
* pairs</em> (see the section <a href="Character.html#unicode">Unicode
* Character Representations</a> in the {@code Character} class for
* more information).
* Index values refer to {@code char} code units, so a supplementary
* character uses two positions in a {@code String}.
* <p>The {@code String} class provides methods for dealing with
* Unicode code points (i.e., characters), in addition to those for
* dealing with Unicode code units (i.e., {@code char} values).
*/
主要意思就是以下几点:
- String类表示字符串,例如“abc”就是String的一个实例。字符串一旦创建它的value是不可变的,因为String的对象是不可变的,所以它们可以被共享;
- String类包括一些方法,比如字符串比较、寻找字串、大小写转换……
- java语言提供了支持字符间的连接操作和将对象转化为字符串的操作,字符间的连接是通过 “+” 来操作的, 它们之所以可以连接是因为通过 StringBuffrer 或者 StringBuilder 的 append 方法实现的,而将对象转化成字符串 是通过Object方法中的toString方法。
- 携带null这个参数给String的构造函数或者方法,String会抛出NullPointerException。
- String 表示一个 UTF-16 格式的字符串。其中的 增补字符 由 代理项对 表示,索引值是指 char 代码单元,因此增补字符在 String 中占用两个位置。
String类的定义:public final class String implements java.io.Serializable, Comparable<String>, CharSequence{}
String实现了java.io.Serializable, Comparable, CharSequence接口。同时String是final类型的不能被继承。
String属性
private final char value[];
这是一个字符数组,并且是final类型,他用于存储字符串内容,从fianl这个关键字中我们可以看出,String的内容一旦被初始化了是不能被更改的。 虽然有这样的例子: String s = “a”; s = “b” 但是,这并不是对s的修改,而是重新指向了新的字符串, 从这里我们也能知道,String其实就是用char[]实现的。
private int hash;
缓存字符串的hash Code,默认值为 0
1 | private static final long serialVersionUID = -6849794470754667710L; |
因为String实现了Serializable接口,所以支持序列化和反序列化支持。
Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。
在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常(InvalidCastException)。
String常用构造方法
使用字符串构造一个String
首先思考:1
2String msg1 = "I Love you";
String msg2 = new String("I Love you");
string1==string2返回false。
我们知道string1是从常量池去取的,而我们new String() 这时候应该在堆内存产生一个String对象,而通过源码可以看到这个 String对象方法是将我们传入的这个 “I Love You !” 对象的value和hash进行复制:1
2
3
4public String (String original){
this.value=original.value;
this.hash = original.hash;
}
jdk7之后字符串常量池放在堆中了,对应的内存模型为: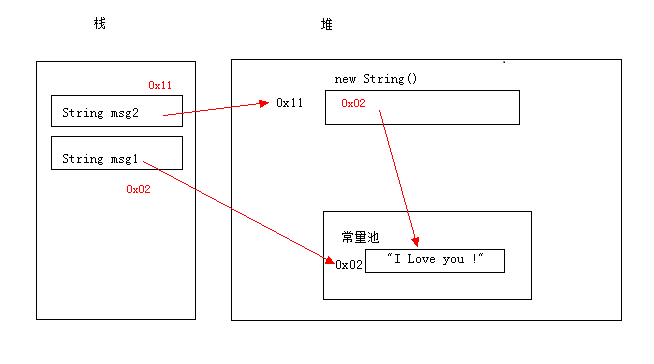
使用字符数组构造String
我们可以创建一个char[],然后传给String构造函数1
2
3
4
5
6char[] c =new char[3];
c[0] = 'I';
c[1] = 'L';
c[0] = 'Y';
String msg = new String(c);
System.out.println(msg);
String的字符数组构造函数为:1
2
3public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
原来它通过 Arrays.copyOf 把我们的char直接复制给value了! 其实我们应该也猜到了,String里面的value就是char数组!
使用字节数组构造String
在Java中,String实例中保存有一个char[]字符数组,char[]字符数组是以unicode码来存储的,String 和 char 为内存形式,byte是网络传输或存储的序列化形式。所以在很多传输和存储的过程中需要将byte[]数组和String进行相互转化。所以,String提供了一系列重载的构造方法来将一个字符数组转化成String,提到byte[]和String之间的相互转换就不得不关注编码问题。String(byte[] bytes, Charset charset)是指通过charset来解码指定的byte数组,将其解码成unicode的char[]数组,够造成新的String。
这里的bytes字节流是使用charset进行编码的,想要将他转换成unicode的char[]数组,而又保证不出现乱码,那就要指定其解码方式
同样使用字节数组来构造String也有很多种形式,按照是否指定解码方式分的话可以分为两种:
String(byte bytes[]) String(byte bytes[], int offset, int length)
String(byte bytes[], Charset charset)
String(byte bytes[], String charsetName)
String(byte bytes[], int offset, int length, Charset charset)
String(byte bytes[], int offset, int length, String charsetName)
如果我们在使用byte[]构造String的时候,使用的是下面这四种构造方法(带有charsetName或者charset参数)的一种的话,那么就会使用StringCoding.decode方法进行解码,使用的解码的字符集就是我们指定的charsetName或者charset。 我们在使用byte[]构造String的时候,如果没有指明解码使用的字符集的话,那么StringCoding的decode方法首先调用系统的默认编码格式,如果没有指定编码格式则默认使用ISO-8859-1编码格式进行编码操作。主要体现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21static char[] decode(byte[] ba, int off, int len) {
String csn = Charset.defaultCharset().name();
try {
// use charset name decode() variant which provides caching.
return decode(csn, ba, off, len);
} catch (UnsupportedEncodingException x) {
warnUnsupportedCharset(csn);
}
try {
return decode("ISO-8859-1", ba, off, len);
} catch (UnsupportedEncodingException x) {
// If this code is hit during VM initialization, MessageUtils is
// the only way we will be able to get any kind of error message.
MessageUtils.err("ISO-8859-1 charset not available: "
+ x.toString());
// If we can not find ISO-8859-1 (a required encoding) then things
// are seriously wrong with the installation.
System.exit(1);
return null;
}
}
String常用方法
charAt(int index)
1 | String msg = "I Love you" |
charAt(int index)方法根据索引返回Char值。
charAt(int index)方法的源码如下:1
2
3
4
5
6public char charAt(int index) {
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];
}
可以看出charAt()方法的源码实现其实就是字符串对应的value数组返回它索引值对应的字符。
equals(Object anObject)
equals我们通常用于比较是否相同,先看看下面的例子输出的是什么?1
2
3
4
5
6
7String s = "I Love you";
String s1 = "I Love you";
String s2 = new String("I Love you");
System.out.println(s==s1);
System.out.println(s.equals(s1));
System.out.println(s==s2);
System.out.println(s.equals(s2));
输出结果为:true,true,false,true
可能有些人会奇怪会什么 s == s2 是false? 他们不是都是是 ““I Love You !” 吗? 这时候我们就要来看看 == 和 equals 的区别了!
其实 == 比较的是他们的地址值(hashcode),我们知道String是不可变的,我们可以知道s 和 s1 指向的都是 “I Love You !”;所以他们的hashcode是一样的。所以返回true; 而s 和 s2 他们指向的地址是不一样的所以是false;
可能此刻有人会疑惑那么为什么s.equals(s2)返回的是true了。这时候我们应该可以猜到equals应该判断的不是 两个对象间的hashcode吧,我们看下源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
该方法首先判断this == anObject ?,也就是说判断要比较的对象和当前对象是不是同一个对象,如果是直接返回true,如不是再继续比较,然后在判断anObject是不是String类型的,如果不是,直接返回false,如果是再继续比较,到了能终于比较字符数组的时候,他还是先比较了两个数组的长度,不一样直接返回false,一样再逐一比较值。
hashCode
hashCode的实现其实就是使用数学公式:s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
s[i]是string的第i个字符,n是String的长度。那为什么这里用31,而不是其它数呢? 计算机的乘法涉及到移位计算。当一个数乘以2时,就直接拿该数左移一位即可!选择31原因是因为31是一个素数!
在存储数据计算hash地址的时候,我们希望尽量减少有同样的hash地址,所谓“冲突”。如果使用相同hash地址的数据过多,那么这些数据所组成的hash链就更长,从而降低了查询效率!所以在选择系数的时候要选择尽量长的系数并且让乘法尽量不要溢出的系数,因为如果计算出来的hash地址越大,所谓的“冲突”就越少,查找起来效率也会提高。
31可以 由i*31== (i<<5)-1来表示,现在很多虚拟机里面都有做相关优化,使用31的原因可能是为了更好的分配hash地址,并且31只占用5bits!
在java乘法中如果数字相乘过大会导致溢出的问题,从而导致数据的丢失.
而31则是素数(质数)而且不是很长的数字,最终它被选择为相乘的系数的原因不过与此!
在Java中,整型数是32位的,也就是说最多有2^32= 4294967296个整数,将任意一个字符串,经过hashCode计算之后,得到的整数应该在这4294967296数之中。那么,最多有 4294967297个不同的字符串作hashCode之后,肯定有两个结果是一样的, hashCode可以保证相同的字符串的hash值肯定相同,但是,hash值相同并不一定是value值就相同。
endsWith(String suffix)
有时候我们可能会判断字符串是否以指定的后缀结束。例如我们有获取的图片路径,判断他是不是以.jpg结尾的:1
2String s = "canglaoshi.jpg";
System.out.println(s.endsWith(".jpg"));//true
那么endsWith()内部是怎么判断的呢?我们看endsWith()的源码:1
2
3public boolean endsWith(String suffix) {
return startsWith(suffix, value.length - suffix.value.length);
}
它又调用startsWith(String prefix, int toffset)方法,我们来看startsWith(String prefix, int toffset)的源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public boolean startsWith(String prefix, int toffset) {
char ta[] = value;
int to = toffset;
char pa[] = prefix.value;
int po = 0;
int pc = prefix.value.length;
// Note: toffset might be near -1>>>1.
if ((toffset < 0) || (toffset > value.length - pc)) {
return false;
}
while (--pc >= 0) {
if (ta[to++] != pa[po++]) {
return false;
}
}
return true;
}
startsWith() 方法用于检测字符串是否以指定的前缀开始。
prefix – 前缀。
toffset – 字符串中开始查找的位置。
用 ta[] 这个数组来存放 “canglaoshi.jpg”; 用 int to 来接收 “canglaoshi.jpg”的长度(14) 减去 “.jpg” 的长度(4) = 10;用 pa[] 来存放 “.jpg”;用int pc 来接收 “.jpg”的长度;最后就是以pc为次数进行遍历ta[]从下标为to开始,pa[] 从下标为0开始逐一判断,如果相同就返回true!
replace(char oldChar, char newChar)
返回一个新的字符串,它是通过用 newChar 替换此字符串中出现的所有 oldChar 得到的。 那么问题来了,下面这一段输出的是什么呢?String s = "I Love you"; s.replace("Love","Miss");System.out.println(s);
因为String是不可变的,所以s还是I Love you,而String s2 = s.replace(“Love”,”Miss”);这样s2才是”I Miss you“;
replace(char oldChar, char newChar)方法的源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
int len = value.length;
int i = -1;
char[] val = value; /* avoid getfield opcode */
while (++i < len) {
if (val[i] == oldChar) {
break;
}
}
if (i < len) {
char buf[] = new char[len];
for (int j = 0; j < i; j++) {
buf[j] = val[j];
}
while (i < len) {
char c = val[i];
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
return new String(buf, true);
}
}
return this;
}
substring(int beginIndex)
返回一个新的字符串,它是此字符串的一个子字符串。 可以理解为截取字符串,它的实现就是用数组的copyOfRange将指定数组的指定范围复制到一个新数组:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
int subLen = endIndex - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}
String.valueOf和Integer.toString的区别
接下来我们看以下这段代码,我们有三种方式将一个int类型的变量变成呢过String类型,那么他们有什么区别?1
2
3
41.int i = 5;
2.String i1 = "" + i;
3.String i2 = String.valueOf(i);
4.String i3 = Integer.toString(i);
1、第三行和第四行没有任何区别,因为String.valueOf(i)也是调用Integer.toString(i)来实现的。 2、第二行代码其实是String i1 = (new StringBuilder()).append(i).toString();,首先创建一个StringBuilder对象,然后再调用append方法,再调用toString方法。
最后,至于String为什么要设置为final的呢?可以进一步思考。